一、GoldenDict基本介绍
GoldenDict 是一款开源的词典软件,它具有高度的定制性,可以自定义软件界面,它支持导入词典数据、调用外部网站和自定义程序等功能,对于需要 在学习中阅读英文文献时非常方便使用。在 Debian12 中可以直接通过 apt 命令下载该软件
sudo apt update
sudo apt install goldendict
下载完毕后,软件界面如下:
在上面工具栏的编辑 -> 首选项 -> 界面可以设置界面语言,并且可以配置内置的一些主题风格,本文不讨论如何自定义界面风格。在编辑 -> 首选项 -> 词典可以配置词典数据来源。GoldenDict 支持多种词典来源,包括本地的词典数据、远程词典服务器、调用搜索引擎和调用脚本程序等。本文会给出一些在网络上搜集的本地词典资源(感谢这些资源的提供者),并给出一个调用百度官方api进行翻译的 python 脚本。
二、词典资源配置
1.本地词典资源
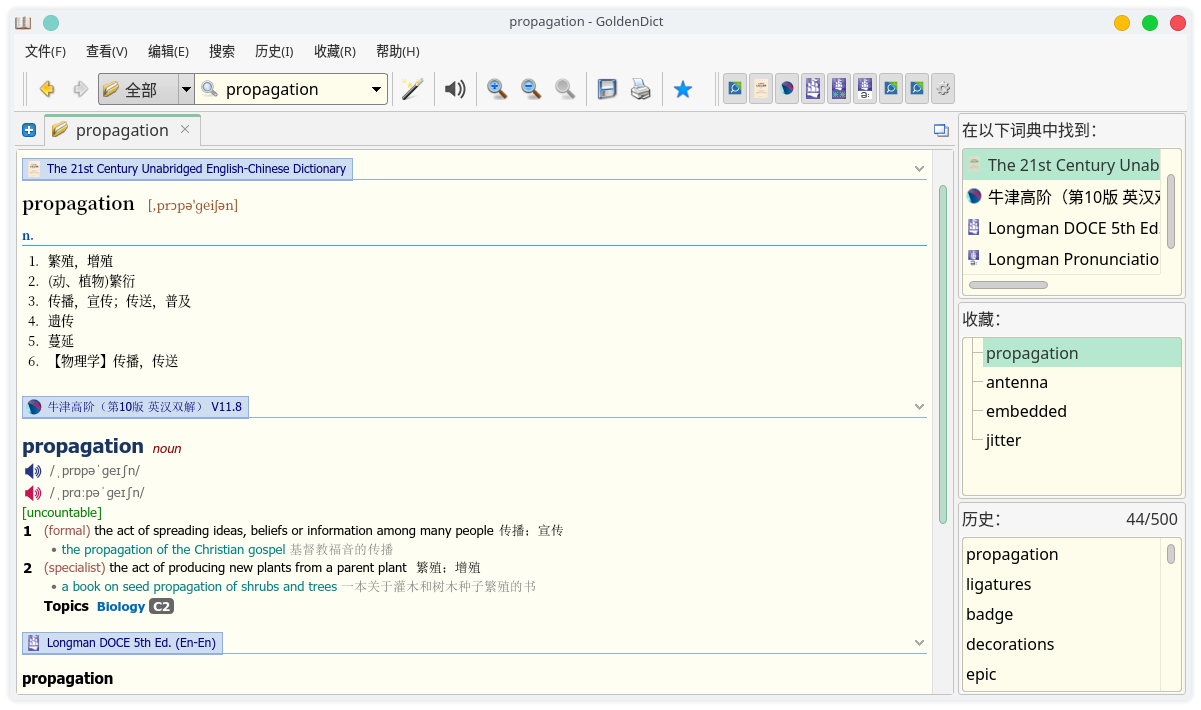
打开编辑 -> 首选项 -> 词典 -> 词典来源 -> 文件,这里可以配置词典文件的路径,如果是文件夹路径需要勾上递归搜索,然后点击应用,这样 GoldenDict 会扫描所有指定的词典文件,并为其生成索引。如果词典数量比较多这个过程会比较漫长,这取决于你的电脑的性能。索引生成完毕后这些词典就可以使用了,索引文件会存储在本地磁盘中,下一次打开不需要重新生成了。我自己用的词典资源: 词典资源 提取码: bp47。示例效果如图所示:
2. 调用百度翻译接口
拥有这些本地词典后,GoldenDict 会帮助你从这些本地词典搜索你要查询的单词或者词语,只要你的词典中有对应的记录即可。但是GoldenDict并不支持句子翻译,即它不会把句子拆成一组单词分别去查询,除非你的词典中有这样一条句子的翻译记录。因此我考虑将百度翻译接入到 GoldenDict 中这样方便进行一些简短的句子翻译。 首先需要在百度翻译api注册账户,选择通用翻译服务,进行认证后高级版通用翻译服务每个月会有一定量的免费额度。然后在管理控制台获取你的APP ID和密钥,替换下面代码中的 APP ID 和密钥,并配置日志文件路径:
import requests
import random
import re
from hashlib import md5
import sys
import time
# 设置你自己的appid和appkey
appid = 'xxxxxxxxxxxxxxxxxx'
appkey = 'xxxxxxxxxxxxxxxxxx'
EN_LIMIT = 800 # 每800个英文字符添加一个换行符
ZH_LIMIT = 300 # 每300个汉字添加一个换行符
EN_MIN_NUM = 8
ZH_MIN_NUM = 5
def hasZhChar(text):
pattern = re.compile(r'[\u4e00-\u9fa5]')
match = pattern.search(text)
return bool(match)
def make_md5(s, encoding='utf-8'):
return md5(s.encode(encoding)).hexdigest()
def full2half(s): #全角转成半角
n = ''
for char in s:
num = ord(char)
if num == 0x3000:
num = 32
elif 0xFF01 <=num <= 0xFF5E:
num -= 0xFEE0
num = chr(num)
n += num
return n
def split_data(sentences, limit):
data = ""
if len(sentences) < EN_LIMIT:
data = sentences
else:
position = EN_LIMIT
while sentences[position] != ' ':
position -= 1
data += sentences[:position] + '\n'
data += split_data(sentences[position + 1:], limit)
return data
from_lang = 'en'
to_lang = 'zh'
endpoint = 'http://api.fanyi.baidu.com'
path = '/api/trans/vip/translate'
url = endpoint + path
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
today = time.strftime("%Y-%m-%d", time.localtime())
if __name__ == '__main__':
sentences = full2half(sys.argv[1].replace('\n', ' '))
salt = random.randint(32768, 65536)
if hasZhChar(sentences):
from_lang = 'zh'
to_lang = 'en'
if len(sentences) < ZH_MIN_NUM:
print(f"汉字数量小于{ZH_MIN_NUM}个,不翻译")
sys.exit(0)
else:
from_lang = 'en'
to_lang = 'zh'
if len(sentences.split(' ')) < EN_MIN_NUM:
print(f"单词数量小于{EN_MIN_NUM}个,不翻译")
sys.exit(0)
# Build request
query = split_data(sentences, EN_LIMIT) if from_lang == 'en' else split_data(sentences, ZH_LIMIT)
sign = make_md5(appid + query + str(salt) + appkey)
payload = {'appid': appid, 'q': query, 'from': from_lang, 'to': to_lang, 'salt': salt, 'sign': sign}
# Send request
r = requests.post(url, params=payload, headers=headers)
result = r.json()
if "error_code" in result:
print("Error: ", result)
print("length: ", len(query))
sys.exit(0)
res = ""
for item in result["trans_result"]:
res += item["dst"] + ' '
print(res)
然后需要在 GoldenDict 中配置,打开编辑 -> 词典 -> 词典来源 -> 程序,添加下面一条记录:
| 已启用 | 类型 | 名称 | 命令行 |
|---|---|---|---|
| ✔ | 文本 | Baidu | python 你的python脚本的绝对路径 %GDWORD% |
为了方便使用 GoldenDict,而不是每次都打开软件然后复制进去,我们需要启用编辑 -> 首选项 -> 热键,然后勾上使用Ctrl + C + C获取剪切板的热键,这样 GoldenDict 只要在后台启动,我们就可以使用热键调出翻译窗口了,效果如图所示:

上面的代码没有像图片中一样提供实时获取额度的功能,这个功能和真实的额度有一些小偏差,而且存在一些小 bug ,因此就不放上来了。读者可以自行修改代码实现自定义功能。 当然,百度翻译api网站的控制台可以查看每月的额度,只是不是实时的。